

Hello fellow Proxmox enjoyers!
I have questions regarding the ZFS disk IO stats and hope you all may be able to help me understand.
Setup (hardware, software)
I have Proxmox VE installed on a ZFS mirror (2x 500 GB M.2 PCIe SSD) rpool . The data (VMs, disks) resides on a seperate ZFS RAID-Z1 (3x 4TB SATA SSD) data_raid.
I use ~2 TB of all that, 1.6 TB being data (movies, videos, music, old data + game setup files, …).
I have 6 VMs, all for my use alone, so there’s not much going on there.
Question 1 - costant disk write going on?
I have a monitoring setup (CheckMK) to monitor my server and VMs. This monitoring reports a constant write IO operation for the disks, ongoing, without any interruption, of 20+ MB/s.

I think the monitoring gets the data from zpool iostat, so I watched it with watch -n 1 'sudo zpool iostat', but the numbers didn’t seem to change.
It has been the exact same operations and bandwidth read / write for the last minute or so (after taking a while for writing this, it now lists 543 read ops instead of 545).
Every 1.0s: sudo zpool iostat
capacity operations bandwidth
pool alloc free read write read write
---------- ----- ----- ----- ----- ----- -----
data_raid 2.29T 8.61T 545 350 17.2M 21.5M
rpool 4.16G 456G 0 54 8.69K 2.21M
---------- ----- ----- ----- ----- ----- -----
The same happens if I use -lv or -w flags for zpool iostat.
So, are there really constantly 350 write operations going on? Or does it just not update the IO stats all too often?
Question 2 - what about disk longevity?
This isn’t my first homelab-setup, but it is my first own ZFS- and RAID-setup. If somebody has any SSD-RAID or SSD-ZFS experiences to share, I’d like to hear them.
The disks I’m using are:
- 3x Samsung SSD 870 EVO 4TB for
data_raid - 2x Samsung SSD 980 500GB M.2 for
rpool
Best regards from a fellow rabbit-hole-enjoyer.
You must log in or # to comment.
I’ll concur with mlfh, the constant Proxmox corosync writes and gawd knows what else have a reputation for ‘cutting through commercial ssds like a torch through tissue paper’ (that’s frequently dropped on their forum.)
Also, yes. Enterprise SSD. You get at least 10x the lifespan, depending on the type.I think some folks just use LVM for the OS on SSD. I’ve done it myself in some circumstances, although I am a ZFS fan.
My homelab runs a zfs mirror raid for a secondary datastore (ie this is NOT the OS drive) on a pair of commercial grade lexar 790 NVMe. Both drives have 0% usage after most of a year in service, although it hosts several VMs that run 24/7.
Yeah, I guess I should’ve put like +50% more money into it and gotten some Enterprise SSDs instead. Well, what’s done is done now.
I’ll try replacing the disks with enterprise SSDs when they die, which will probably happen fast, seeing as the wearout is already at 1% after 1 month of low usage.
What do you think about Samsung OEM Datacenter SSD PM893 3,84 TB?
Thanks for taking the time to answer!
It looks like that part is a Mixed Use drive. Particularly in this 6gb interface, you’ll enjoy something with equal read/write, so that seems like a reasonable choice. If you are interested in comparing to their other drives, they have a great configurator on their page.
https://semiconductor.samsung.com/ssd/datacenter-ssd/pm893/I know it’s irritating to watch your SSDs burn up, but with 1% used in a month … your current drives will last at least a couple years. You won’t have to make this decision for a while yet. I think the thing to do is check it occasionally, and plan ahead when it gets low. You may well decide that the cheaper drives are worth it in the end.
Thank you very much for your input, I’ll definitely have to go with business drives whenever the current ones die.
Thankfully, I do have monitoring for SMART data and drive health, so I’ll be warned before something bad happens.
I delved into exactly this when I was running proxmox on consumer ssds, since they were wearing out so fast.
Proxmox does a ton of logging, and a ton of small updates to places like /etc/pve and /var/lib/pve-cluster as part of cluster communications, and also to /var/lib/rrdcached for the web ui metrics dashboard, etc. All of these small writes go through huge amounts of write amplification via zfs, so a small write to the filesystem ends up being quite a large write to the backing disk itself.
I found that vms running on the same zfs pool didn’t have quite the degree of write amplification when their writes were cached - they would accumulate their small writes into one large one at intervals, and amplification on the larger dump would be smaller.
For a while I worked on identifying everywhere these small writes were happening, and backing those directories with hdds instead of ssds, moving /var/log from each vm onto its own disk and moving it onto the same hdd-backed zpool, and my disk wearout issues mostly stopped.
Eventually, though, I found some super cheap retired enterprise ssds on ebay, and moved everything back to the much simpler stock configuration. Back to high sustained ssd writes, but I’m 3 years in and still at only around 2% wearout. They should last until the heat death of the universe.
Is “Discard” the write caching you refer to?
Or are you talking about the actual Write Cache?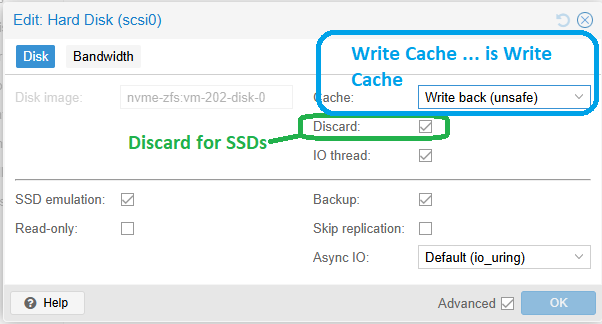
The actual write cache there - writeback accumulates writes before flushing them in a larger chunk. It doesn’t make a huge difference, nor did tweaking zfs cache settings when I tried it a few years ago, but it can help if the guest is doing a constant stream of very small writes.
So I just looked it up: According to Proxmox VE “disks” interface, my SATA SSD drives have 1% wearout after ~1 month of low usage. That seems pretty horrible.
I guess I’m going to wait until they die and buy enterprise SSDs as a replacement.
I’m definitely not going to use HDDs, as the server is in my living room and I’m not going to tolerate constant HDD sounds.
[EDIT] I don’t even have a cluster, it’s just a single Proxmox VE on a single server using ZFS and it’s still writing itself to death.
[EDIT2] What do you think about Samsung OEM Datacenter SSD PM893 3,84 TB?
Thanks for your input!
The datasheet for the Samsung PM893 3.84TB drives say they’re warrantied for 7PBW and 2 million hours MTBF (can write 7PB or run for 2 million hours before average drive failure). Quite pricey, but looks like it’ll run forever in a home environment.
Good luck!
Thank you very much for your input. I’ll definitely have to go for the business models whenever the current ones die.
I knew I would make some mistake and learn something new, with this being my first real server-PC (instead of mini-pc or raspberry pi) and RAID. I just wished it wasn’t that pricey of a mistake :(
I wouldn’t say it’s a big mistake, you’ve likely still got a few years left on your current drives as-is. And you can replace them with same- or larger-capacity drives one at a time to spread the cost out.
Keep an eye out for retired enterprise ssds on ebay or the like - I got lucky and found mine there for $20 each, with 5 years of uptime but basically nothing written to them so no wearout at all - probably just sat in a server with static data for a full refresh cycle. They’ve been great.
Sadly, it seems I cannot replace the disks one-by-one. At least not if I don’t upgrade the SSD size to greater than 4TB at the same time.
The consumer 4TB SSDs yield 3,64 TiB, whereas the datacenter 4TB SSDs seem to yield 3,49 TiB. As far as I know, one cannot replace a zfs raid z1 drive with a smaller one. I’ll have to watch the current consumer SSDs closely and be prepared for when I’ll have to switch them.
I’m not all too sure about buying used IT / stuff in general from ebay, but I’ll have a look, thanks!
If you want enterprise gear on the cheap, yes. Ebay.
There are regular vendors on Ebay with thousands of verified sales. Go with those till you figure it all out.
You can definitely make bad choices, but even when I’ve gotten bad drives, the vendor just immediately refunded the money, like that day.
